Tout le monde connaît le logiciel Photoshop, développé par Adobe. Véritable référence dans le milieu de la retouche d’image, celui-ci permet aussi bien d’améliorer certains portraits en nettoyant le visage de leurs impuretés, que de détourner complètement certaines photos de leur réalité via des montages très élaborés. Il est donc tout à fait possible de faire croire aux lecteurs des magazines qu’un mannequin en maillot de bain n’a pas une trace de cellulite ni une seul ride, ou qu’un personnage se retrouve dans un environnement factice, alors qu’il a en réalité été pris en photo en studio, sur fond blanc.
Mais quel rapport avec le son ?
Dans une rubrique son, vous êtes en droit de vous le demander, et j’allais y venir. Après l’illusion visuelle, Adobe s’est lancé dans l’illusion audio. Ainsi, lors de l’Adobe Max 2016 le 4 novembre dernier, Zeyu Jin, développeur chez Adobe, présenta le logiciel VoCo (pour VOice COnversion), un outil de synthèse vocale, permettant de faire dire ce que l’on veut à un enregistrement existant de voix, selon un texte défini par l’utilisateur. En d’autres termes, le texte que vous écrirez sera lu par une voix dont vous posséderez un enregistrement.
En soit, le principe du text-to-speech (littéralement « texte à parole ») n’est pas nouveau puisqu’il existe déjà depuis les années 70. On se souviendra notamment du jeu Speak & Spell de Texas Instrument, qui demandait d’épeler un mot qu’il venait de prononcer.
De plus, le procédé est bien courant puisqu’on le retrouve très souvent dans notre quotidien. Prenez les annonces de certains transports publics comme ceux des transports lausannois ou genevois. Chaque arrêt est annoncé par une voix synthétique. Celle-ci est générée par un logiciel en ligne nommé AcaBox. Faites un petit test. Cliquez ici et sélectionnez French, puis choisissez la voix Claire et tapez le texte «Prochain arrêt, Georgette », ça vous rappellera qqch… 🙂
On retrouve aussi cette technologie depuis des années dans d’autres outils numériques tels que les GPS ou les smartphones (avec Siri notamment). Bien qu’on ne puisse ici pas leur faire dire ce que l’on veut (les réponses étant générées automatiquement par l’appareil), le principe est toutefois le même puisque la voix énoncera ce que l’appareil lui aura dit de répondre.
Quel en est le principe ?
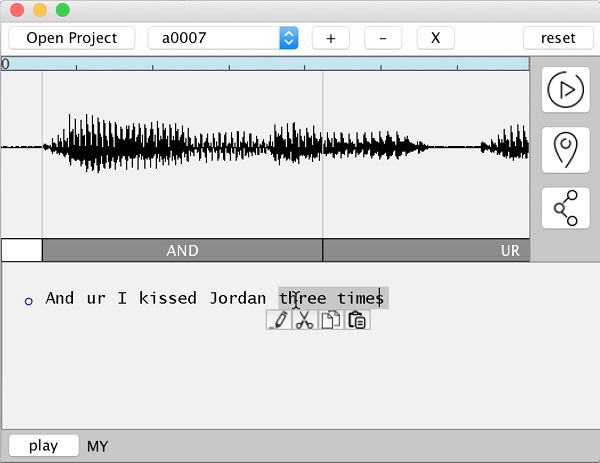
Sur la base d’un enregistrement d’une certaine durée, le logiciel VoCo scanne l’ensemble de l’extrait pour y trouver et isoler les différentes syllabes ou phonèmes (chacun des sons distincts qui construit un langage). Il se charge ensuite de choisir dans ces échantillons les phonèmes ou mots entiers qui conviendront le mieux (en terme de transition ou tonalité), pour les assembler et créer les phrases correspondantes au texte défini par l’utilisateur, de la façon la plus réaliste possible.
Pour créer Siri par exemple (en anglais), c’est la comédienne américaine Susan Bennett qui a prêté sa voix. Des séances quotidiennes de 4h d’enregistrement pendant un mois ont permis de créer la base de donnée nécessaire à générer l’audio de n’importe quelle phrase que pourrait dire la voix de l’iPhone.

Alors en quoi est-ce que VoCo est une (r)évolution ?
Tout d’abord, bien que la démonstration effectuée lors de la présentation du logiciel VoCo en live n’était pas parfaite, on devrait pouvoir atteindre des résultats encore jamais égalé en terme de réalisme. Pour reprendre l’exemple des annonces des transports en public ou de Siri, la qualité est intéressante certes, mais souvent loin d’être parfaite. On décèle toujours ici ou là des petits sauts de voix étrange qui suffisent à déceler la supercherie et rendre cela terriblement synthétique. Le logiciel d’Adobe devrait y remédier et surtout permettre d’automatiser le système de découpe des phonèmes, là où ce processus devait être fait manuellement par un ingénieur du son jusqu’alors. Le gain de temps est donc énorme et maintenant à la portée de tous !
Ensuite, la programme offrirait la possibilité de créer un text-to-speech sur la base de n’importe quelle voix issue de vos propres archives : un comédien, un ami, ou des sources prises sur internet par exemple. On ne se limite donc plus au choix proposé par le site cité plus haut et cela élargit et personnalise grandement l’offre des voix. Tout ce dont il « suffit », c’est d’avoir un enregistrement d’environ 20 minutes (selon les développeurs) pour que le programme puisse décomposer diverses variations de syllabes ou phonèmes. On est déjà bien loin des dizaines d’heure d’enregistrement qui ont été nécessaire à l’élaboration de Siri.
Quelle application pour ce programme?
Bien que la question de la prouesse technologique ne se pose même pas, on peut toutefois se demander comment le logiciel va être utilisé.
Est-il destiné à remplacer les comédiens voix-off ? Cela paraît peut réalisable tant la marge de manœuvre sera réduite face à un véritable comédien présent en studio, qui sera en mesure de délivrer une interprétation variable, étendue et parfaite en quelques secondes. Aucune précision pour l’instant là-dessus, mais on doute que VoCo permette de transformer des enregistrements d’une voix calme en quelque chose de plus dynamique, sans que cela sonne trop synthétique.
VoCo pourrait toutefois permettre de corriger une erreur ou un terme modifié post-enregistrement par un client. L’équipe d’Adobe met d’ailleurs en avant le fait qu’il sera possible de retravailler ainsi des podcasts ou livre audio, sans avoir besoin de faire revenir le comédien (c’est d’ailleurs la seule utilisation qu’ils suggèrent pour l’instant). On peut déjà imaginer que cela créera quelque bisbilles entre les studios et les comédiens puisque ces derniers, payés habituellement pour enregistrer à nouveau un texte modifié, pourraient s’avérer être victimes de cette technologie.
Est-si cela devenait une arme ?
Comme annoncé depuis le début de cet article, il deviendra donc possible (et surtout facile) de faire dire ce que l’on veut à une voix pré-enregistrée. On imagine déjà tous les canulars radio ou téléphoniques qui pourront en découler. Ça, c’est le côté fun de la chose. Mais on peut se demander aussi si cet outil n’a pas un côté dangereux, puisqu’il sera aisé de détourner les propos de quelqu’un, comme celui d’un personnage politique par exemple, en se basant sur des enregistrements de discours publics, repris sur internet. Les banques, utilisant des vérifications à empreintes vocales pour attester que le client est celui qu’il prétend être au téléphone, pourraient également se trouver concernées par une potentielle usurpation d’identité.
Plusieurs experts se disent donc perplexes ou horrifiés par ce programme, mettant en avant que Photoshop a déjà rendu beaucoup plus difficile le travail des journalistes, avocats ou toute personne utilisant les images digitales comme évidences. Qui ne s’est jamais dit en voyant une photo hallucinante « mais c’est pas possible, c’est un montage Photoshop ! ». Le doute s’est déjà installé quant à l’image, si celui-ci apparaît avec l’audio, les perspectives ne sont pas forcément réjouissantes.
Pour anticiper cela, Zeyu Jin, le présentateur du projet, précise que les fichiers auront des « watermarks », un tatouage numérique invisible, mais inscrit dans le code, permettant de tracer un extrait audio et de savoir s’il a été modifiée ou non, par rapport à la version originale. Bien que l’idée soit louable, on imagine bien que l’auditeur lambda ne prendra pas forcément le temps (ni ne saura comment faire) pour vérifier si l’extrait qu’il vient d’entendre est celui d’origine.
Il va donc être intéressant de pouvoir observer ces prochains temps les usages divers du programme VoCo. En tant qu’homme du son, je suis véritablement fasciné par la prouesse technologique mais reste encore dubitatif quant à son utilisation. Pour l’instant, il ne s’agit que d’un prototype et aucune date de sortie n’a encore été révélée, mais on peut toutefois se douter qu’il sera intégré sous forme de plugin, dans la prochaine édition du logiciel Audition, dans la Creative Cloud d’Adobe.
Pour vous faire une idée du programme Voco, voici la présentation du projet.